Data Pruning in Lambda-Architekturen
Reporting-Systeme leiden typischerweise unter der Last der enormen Datenmengen, die in sie eingespeist werden. Damit diese Datenmengen effizient in Echtzeit ausgewertet werden können, wird die Lambda-Architektur eingesetzt.
Data Pruning in Lambda-Architekturen – Was ist das?
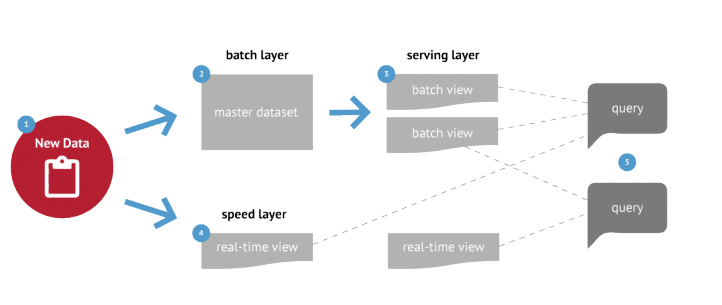
Eintreffende Daten werden parallel in zwei Daten-Pipelines eingeschleust.
Der „Batch Layer“ sorgt neben der Langzeitspeicherung der Rohdaten und für tiefergehende Analysen Backups bei Notfällen .
Im „Serving Layer“ werden Daten so aufbereitet, dass man diese möglichst effizient anzeigen kann. Die Daten werden aber bereits so umgewandelt, dass Standard-Anfragen effizient werden.
Der „Speed Layer“ erlaubt Abfragen auf Echtzeitdaten und wird ständig aktualisiert.
Der Unterschied zwischen „Speed“- und „Batch Layer“ ist die Zugriffsgeschwindigkeit vs. der verfügbare Speichermenge. Während man im „Batch Layer“ mehrere zig Terabyte an Daten problemlos und sicher speichern kann, ist die Zugriffsgeschwindigkeit auf die Daten stark limitiert. Abfragezeiten bewegen sich im Minuten- und Stundenbereich.
Nicht so im „Speed“ Layer.Dieser Layer ist auf Echtzeit-Abfragen fokussiert, kann aber bei Weitem nicht so viele Informationen speichern – typischerweise sind die im Speed Layer verfügbaren Daten im Gigabyte-Bereich.
Was wir tun
Aktuell setzen wir die Lambda-Architektur in unseren Reporting-Systemen ein.
Als Batch Layer verwenden wir in den allermeisten Fällen simple Textdateien, die nach Datenquelle, Kunde und Datum sortiert abgelegt werden. Dies gibt uns die Möglichkeit, bei Bedarf auch nach vielen Jahren Informationen auszulesen -lange nachdem der Adserver, welcher diese Daten erzeugt hat, eingestampft oder aufgekauft wurde.
Im Serving Layer verwenden wir Postgres-Datenbanken, mit denen wir die Daten in Tabellenstrukturen einlesen, die für das effiziente Auslesen in den Reporting-Ansichten optimiert werden. Unsere Erfahrung zeigt dass „Postgresql“ ohne komplexe Replikationsverfahren bis zur Größenordnung von 200 GB die meisten Abfragen in Echtzeit erlaubt.
Um dieses Limit immer einzuhalten, verfolgen wir zwei Strategien:
1. Aufteilung von Kundendaten auf einzelne Datenbanken (lieber verwalten wir hunderte Datenbanken automatisiert als eine, die ständig langsam ist) und
2. Intelligentes Vergessen (Sind die Daten überhaupt noch interessant?)
Der Speed Layer besteht für uns aus mehreren Solr-Indizes. Dies erlaubt uns die effiziente Facettierung und die strukturierte Navigation aller Informationen in Echtzeit.
Schnell gehalten werden die Systeme bei uns durch das intelligente Vergessen, das in unsere Daten-Management-Pipelines eingebettet wird.
Für jeden Datensatz legen wir fest, wie lange diese Daten vorgehalten werden. Typischerweise sind das zwischen 4 und 13 Monate, danach braucht man die Daten nur noch für Referenzzwecke. Wenn bestimmte Kunden eine längere Vorhaltezeit benötigen, bleibt dies optional einstellbar. Für solche Fälle erzeugen wir automatisch spezialisierte Pipelines (abseits von den Tagesgeschäft-Pipelines), die wir je nach Fall optimieren können. Beispielsweise durch stärkere Hardware, Senkung der Aktualisierungshäufigkeit bis zum Punkt, an dem die Zugriffsgeschwindigkeit genügt.
In täglichen Prozessen wird nach jedem Import der Daten überprüft, welche alten Daten sicher aus den Postgres-Datenbanken und aus dem Solr-Index gelöscht werden können.
Aus diesen Maßnahmen resultiert ein schnelles und flüssig laufendes System.