Content aus dem Nichts – Wie generiert eine KI Bilder?

Das Thema Künstliche Intelligenz (KI) kommt immer häufiger im Arbeitsalltag vor. Für die meisten ist das Ganze eine riesige Black Box, die am Ende schönen Content ausspuckt (oder manchmal auch nicht). In diesem Blogbeitrag erklären wir euch in einfachen Schritten, was in dieser Black Box passiert und dass der Content alles andere als aus dem Nichts kommt.
KI und der Mensch sind sich nicht so unähnlich
Wenn man jemanden darum bittet einen Baum zu malen, kann er:sie sich an seinem:ihren Gedächtnis orientieren oder schaut aus dem Fenster und sieht Bäume. So funktioniert ein KI-Bildgenerator auch. In seinem „Gedächtnis“ sind zahlreiche Bilder, die als „Baum“ gekennzeichnet sind, eingespeist worden. Das System erkennt die Eigenschaften, die einen Baum ausmachen, z.B. Baumkrone, Stamm, Äste. Auf diese Weise kann ein Bild von einem Baum generiert werden.

Schwieriger wird das Ganze, wenn die Idee wilder wird. Bei „Ein Baum mit Zuckerwatte als Blätter auf einer Autobahn“ hat auch die KI Probleme.

Eine KI hat Schwierigkeiten damit, weil für diese Wortkombination sehr wenig Referenz existiert. Wieso ihr dafür aber trotzdem Ergebnisse bekommt, liegt an den Technologien, die dies ermöglichen.
Die Black Box: GAN und Diffusion Model
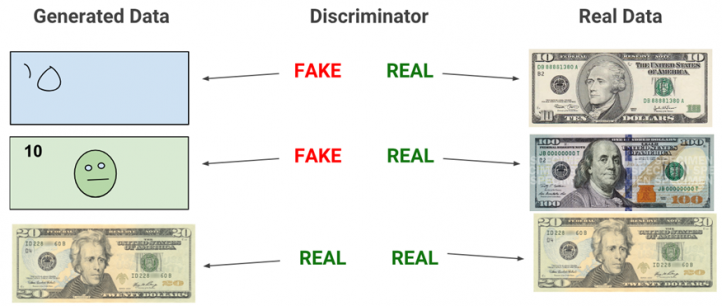
Die zwei gängigsten Methoden sind einmal GAN (Generative Adversial Network) und das Diffusion Model. Bei GAN arbeiten zwei Netze: Eins erstellt (Generator) und eins bewertet (Discriminator). Auf diese Weise entsteht ein Kreislauf, bei welchem beide Netzt dazulernen. Der Generator lernt Bilder zu verbessern und der Discriminator wird besser darin, Fake von Realität zu unterscheiden. In diesem Fall würde der Generator so lange Bäume mit Zuckerwatte als Blätter auf einer Autobahn erstellen, bis der Discriminator keinen Unterschied mehr zum Vergleichsmaterial erkennen kann.
Beim Diffusion Model lernt das System ein Bild zu verrauschen und es wieder zusammenzusetzen. Auf diese Weise lernt das System bestimmte Objekte selbst im verrauschten Zustand noch zu erkennen. Auch hier arbeitet die Technologie mit einer Bildbasis, welche aber nicht zum Vergleichen verwendet wird. Diese Bilder sind mit deskriptiven Captions versehen. Bleiben wir beim Baum mit Blättern aus Zuckerwatte auf einer Autobahn: Die KI sucht nach den Keywords Zuckerwatte, Baum und Autobahn. Die Technologie lernt diese Objekte in den Bildern trotz verrauschtem Zustand zu erkennen und kann sie somit auch generieren.

Ist es wirklich so einfach?
Die ehrliche und kurze Antwort ist Nein. Diese zwei Modelle werden hier nur oberflächlich angerissen und sind vor allem nicht die einzigen zwei Technologien, die für Bildgenerierung verwendet werden. Im Grunde kann man KI auch verwenden, ohne zu wissen, was im Hintergrund passiert. Aber mit einem Grundverständnis für die ganze Thematik, kann euch das Prompten einfacher fallen.