Woher weiß die KI das? Trainingsdaten vs. Live-Suche
Miriam Schrepfer
Miriam Schrepfer- Senior Consultant Content Marketing

Alle sprechen davon, dass die eigenen auf der Website bereitgestellten Informationen zukünftig auch für KI-Tools verfügbar gemacht werden müssen. Für Seitenbetreiber:innen wirft das sofort zwei entscheidende Fragen auf: Woher beziehen Systeme wie ChatGPT, Gemini oder Claude eigentlich ihr Wissen? Und wie können Informationen für diese großen Sprachmodelle (LLMs) am besten verfügbar machen?
Damit ihr eure Website optimal für das KI-Zeitalter rüsten könnt, müsst ihr die Mechanismen im Hintergrund verstehen. Wir haben für euch die wichtigsten Fakten zusammengefasst, damit ihr genau nachvollziehen könnt, wann welche KI einen Live-Crawl eurer Seite startet und wann sie lediglich auf ihr historisches Trainingswissen zurückgreift. Darüber hinaus geben wir dir einen Ausblick, wie du durch geschickte Formulierungen heute schon gezielt steuern kannst, auf welche Datenquellen die KI zugreift, um die Qualität deiner Ergebnisse massiv zu steigern.
Das „Gedächtnis“ der KI – Antrainiertes Wissen vs. Live-Crawl
Wenn Nutzer KIs eine Frage stellen, liefern sie in Sekundenschnelle oft erstaunlich präzise Fakten – es wirkt fast so, als würden sie live in einem gigantischen Lexikon nachschlagen. Doch die technische Realität dahinter sieht etwas anders aus.
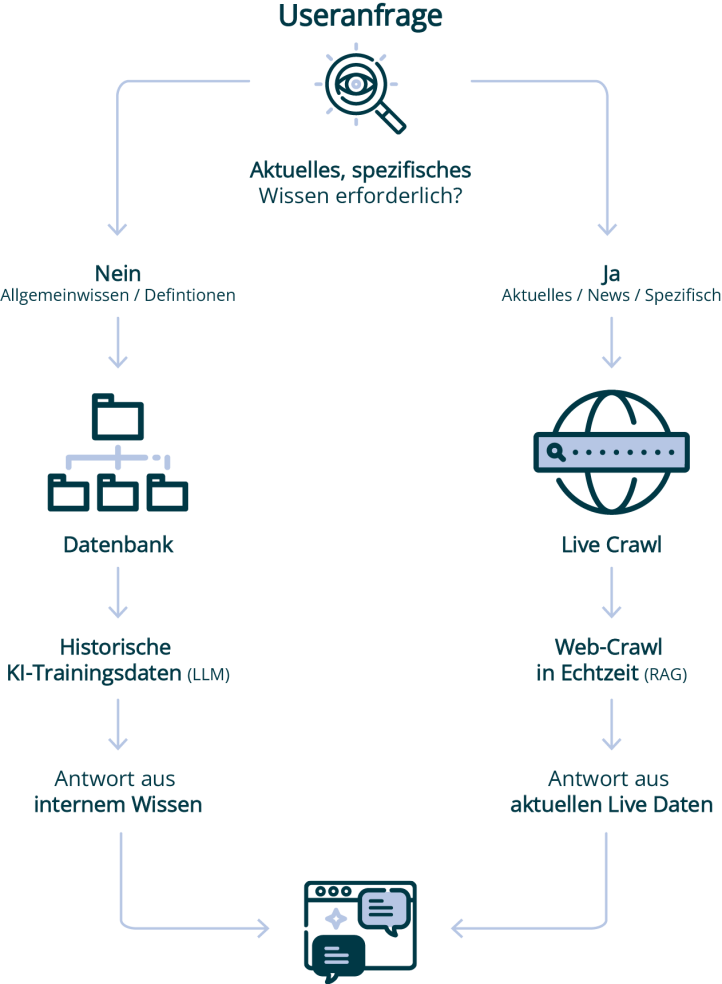
Vorab: nicht jede KI funktioniert nach dem gleichen „Schema F“. Was aber alle künstlichen Intelligenzen eint ist, dass sie auf eine Datenbank zugreifen können, die mit Milliarden von historischen Daten gefüttert wurde.
Doch wer sich aktuelle Informationen erwartet, kann sich auch hier meist auf die KI und ihren Live-Crawl verlassen. Wann welche Daten verwendet werden, siehst du in unserer Grafik.
Die „Datenbank“ (Das Pre-Training): Die KI fragt keine klassische SQL-Datenbank ab, in der Fakten liegen. Das Wissen ist in Milliarden von „Parametern“ oder „Gewichten“ eines neuronalen Netzes codiert. Das bedeutet, das KI-Modell hat Texte gelesen, Muster darin erkannt und „merkt“ sich Konzepte. Das ist das statische Wissen, das mit dem sogenannten „Cut-Off-Datum“ endet. Es ist sozusagen der Stichtag, an dem Large Language Models (LLLMs) zuletzt mit Trainingsdaten gefüttert wurden. Alles, was danach an Ereignisse, Fakten oder Entwicklungen passiert ist, ist der KI ursprünglich nicht bekannt. Das Gefährliche daran: Fragt man die KI nach Informationen, die nach diesem Datum lagen, kann sie falsche Informationen erfinden und quasi „halluzinieren“. Das passiert natürlich nicht nur im Bezug zu konkreten Daten, sondern auch bei angefragten Informationen, zu denen die KI keine Informationen beziehen konnte.
Um Lücken bei aktuellen Informationen vorzubeugen und Fehler zu vermeiden, gibt es den Live-Crawl:
Der Live-Crawl (RAG / Web Browsing): Wenn die KI also nach aktuellen Daten gefragt wird, nutzt sie eine Technik, die oft auf RAG (Retrieval-Augmented Generation) basiert. Das Modell wird kurzfristig quasi zu einem Suchmaschinen-User, sucht im Web nach Informationen (Live-Crawl), liest die Ergebnisse im Hintergrund und fasst sie (ggf. in Kombination mit antrainiertem Wissen) für die Fragestellenden zusammen.
Beispiel:
Wenn wir die KI fragen: „Wer hat die Fußball-WM 2014 gewonnen?“ antwortet sie aus ihrem antrainierten Netzwerk (Pre-Training), weil dieses Faktum millionenfach in den Trainingsdaten vorkam.
Wenn wir aber fragen „Wie ist das Wetter heute in München und was steht in den Lokalnachrichten?“ dann kann das antrainierte Netzwerk nicht auf vorhandene Infos zurückgreifen: Es hat schlicht keine Ahnung. Die KI wirft also ihren Live-Crawler an, zieht die Daten aus dem Web und formuliert daraus eine Antwort.
Wie man durch gezieltes Prompting den Live-Crawler startet
Die KI hat manchmal erschreckend viele menschliche Züge. Einer davon ist, dass selbst sie manchmal „faule Tage hat“ und lieber auf bestehendes Wissen zugreift als auf aktuelle Daten. Doch mit dem richtigen Prompting kannst du den Live-Crawler ganz gezielt selbst anwerfen:
- Nutze explizite Befehle und lass keinen Interpretationsspielraum. Starte deinen Prompt direkt mit Phrasen wie „Suche im Internet nach…“, „Recherchiere online die aktuellsten Entwicklungen zu…“ oder „Durchsuche das Web nach…“.
- Verwende klare Zeitbezüge: Wörter wie „heute“, „aktuell“, „in dieser Woche“ oder das gegenwärtige Jahr signalisieren dem System sofort, dass sein statisches Pre-Training (das Cut-off-Datum) hier nicht ausreicht, um die Frage zu beantworten.
- Fordere Beweise: Ein Prompt wie „Bitte suche online nach XY und nenne mir die Ergebnisse inklusive Links zu den Quellen“ zwingt die KI direkt zum vorhin beschriebenen Grounding. Sie muss den Crawler starten, um echte, klickbare URLs liefern zu können.
Nutzt jede KI die gleichen Methoden?
Wer welche KI nutzt, scheint eine reine Gefühlsentscheidung zu sein. Während die einen auf ChatGPT schwören, sind andere eng mit Gemini oder Claude verbandelt. Doch hat jede KI tatsächlich die gleichen Fähigkeiten und Informationen wie die andere oder unterscheiden sich die Modelle voneinander? Und wenn ja – wie?
- ChatGPT (Weltweiter Marktanteil 60-68%): Ein Mythos der sich hartnäckig hält (und den ChatGPT immer wieder selbst bestätigt) ist, dass es keinen Crawler hat, der auf aktuelle Daten zurückgreifen kann . Doch drückt es sich hier wahrscheinlich missverständlich aus.
Fakt ist: OpenAI nutzt den eigenen Web-Crawler GPTBot, um massenhaft Trainingsdaten für neue Modelle zu sammeln. Für Live-Suchanfragen im Chat nutzt ChatGPT eine Integration der Bing-Suchmaschine. Es sucht also – entgegen teils auffindbarer Angaben – aktiv im Netz.
- Google Gemini (Weltweiter Marktanteil 18-24%): Gemini hat den massiven Vorteil, direkt an der Quelle zu sitzen. Es nutzt die Google-Suche zum sogenannten „Grounding“ der Antworten. Grounding bedeutet, dass die KI gezwungen wird, ihre Aussagen an verifizierbaren, echten Daten zu verankern (zu „erden“). Sie darf nicht mehr einfach nur statistisch plausible Wörter aneinanderreihen, sondern muss ihre Antwort auf handfeste Fakten stützen. Wenn es um Echtzeit-Daten geht, ist Gemini durch die nahtlose Google-Integration also extrem stark.
- Anthropic Claude (Weltweiter Marktanteil 2%): Claude legt den Fokus historisch eher auf analytische Fähigkeiten und ein riesiges Kontextfenster (die Fähigkeit, hunderte Seiten hochgeladener Dokumente auf einmal zu verstehen) als auf die reine Live-Websuche. Zwar kann auch Claude je nach Plattform Web-Suchen durchführen, seine absolute Stärke liegt aber im Verarbeiten mitgelieferter Daten.
Quelle: Similarweb Global AI Tracker
Welche Datenquellen nutzen die KIs?
Um eure Website für KI-Antworten zu optimieren, müsst ihr wissen, welche Suchmaschine die jeweilige KI im Hintergrund anwirft, wenn sie Fakten braucht.
ChatGPT (OpenAI) nutzt Microsoft Bing: Die Live-Suche von ChatGPT ist direkt mit Bing verknüpft. Wenn Nutzer nach aktuellen Produkten, Dienstleistern oder News fragen, durchforstet ChatGPT das Web über die Bing-Infrastruktur.
Gemini (Google) nutzt Google Search: Hier gibt es keine Überraschung. Gemini greift für das Grounding direkt auf den gigantischen, hauseigenen Google-Suchindex zu. Was in der klassischen Google-Suche Relevanz hat, wird auch von Gemini bevorzugt herangezogen.
Claude (Anthropic) nutzt externe APIs: Claude legt den Fokus zwar primär auf die Analyse mitgelieferter Dokumente, nutzt für Live-Websuchen aber oft unabhängige Schnittstellen wie beispielsweise Brave Search.

Was bedeutet das in Bezug auf SEO und AIO?
Für Websitebetreiber ändert sich gerade die komplette Spielwiese. Das klassische SEO (Search Engine Optimization) verschmilzt zunehmend mit AIO (Artificial Intelligence Optimization). Das Ziel ist nicht mehr nur der Klick auf einen blauen Link, sondern als verifizierte Quelle direkt in der KI-Antwort zitiert zu werden.
Daraus ergeben sich drei Handlungsempfehlungen für eure Content-Strategie:
1. Bing darf nicht länger ignoriert werden
Jahrelang wurde Bing in der SEO-Welt eher stiefmütterlich behandelt. Da Millionen von Menschen nun aber über ChatGPT (und damit indirekt über Bing) suchen, müsst ihr eure Präsenz dort pflegen. Ein Setup in den Bing Webmaster Tools ist heute absolute Pflicht.
2. AIO erfordert klare Antworten
KIs suchen im Live-Crawl nach harten Fakten (Entitäten), die sie extrahieren können. Das bedeutet: Nutzt strukturierte Daten (Schema.org), um dem Crawler glasklar zu sagen: Das ist ein Produkt, das ist ein Preis, das ist ein Autor.
Baut W-Fragen in eure Zwischenüberschriften ein und beantwortet diese direkt im ersten Absatz darunter präzise und schnörkellos. Je leichter die KI die Antwort extrahieren kann, desto wahrscheinlicher werdet ihr als Quelle verlinkt.
3. Eure robots.txt ist der Türsteher für die KI KI-Anbieter schicken eigene Bot-Armeen durchs Netz, um Trainingsdaten zu sammeln. Wenn eure IT in der robots.txt Datei vorsorglich User-Agents wie GPTBot (OpenAI), ClaudeBot (Anthropic) oder Google-Extended blockiert, schließt ihr euch selbst aus der Wissensdatenbank der KIs aus. Eure Marke findet in der nächsten KI-Generation dann schlichtweg nicht mehr statt.
So macht ihr eure Website bereit für die LLMs
ChatGPT, Gemini und Claude sind dynamische Recherche-Assistenten, die aktiv das Live-Web durchforsten, um ihre Antworten mit echten Daten zu untermauern.
Für euch als Seitenbetreiber bedeutet das einen klaren Paradigmenwechsel vom klassischen SEO hin zur AIO. Um künftig in den Antworten der KIs als verlässliche Quelle zitiert zu werden, solltet ihr diese drei goldenen Regeln verinnerlichen:
- Google bleibt durch Gemini der Platzhirsch, aber Microsoft Bing feiert durch ChatGPT ein massives Comeback. Behaltet beide Suchmaschinen im Auge!
- Nutzt strukturierte Daten und beantwortet W-Fragen direkt und präzise. Je einfacher ein Crawler eure Fakten extrahieren kann, desto eher werdet ihr als Quelle verlinkt.
- Überprüft regelmäßig eure robots.txt. Wer die Bots der KI-Anbieter aussperrt, macht seine Marke für die nächste Generation der Suchanfragen schlichtweg unsichtbar.
Kurzgesagt: Eure Inhalte werden ja schon lange nicht mehr nur von Menschen gelesen, sondern von Maschinen analysiert, zusammengefasst und neu aufbereitet. Wer seine Website jetzt technisch und inhaltlich klar strukturiert, macht es der KI leicht – und sichert sich so auch im AIO-Zeitalter die wertvolle Aufmerksamkeit der Nutzer.
Warum die Datenbereitstellung für Unternehmen entscheidend ist (GEO)
Genauso wichtig wie die Steuerung durch den Nutzer ist es umgekehrt für dich und dein Team, die richtigen Daten für diese KIs bereitzustellen. Damit ChatGPT, Gemini und Co. dein Unternehmen bei einer Suchanfrage korrekt finden und empfehlen können, müssen deine Inhalte für den KI-Crawl optimiert sein. Das Stichwort hierfür lautet GEO (Generative Engine Optimization). Es geht darum, Informationen so aufzubereiten, dass sie von KI-Modellen verstanden und als vertrauenswürdige Quellen genutzt werden. Unser Team hilft dir gerne dabei, deine Online-Präsenz für GEO zu optimieren, damit du in den Antworten der KIs präsent bist!
Wissenschaftliche Quellen / Paper
- Zur Live-Suche (RAG):
- Paper: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020)
- Erklärt, wie man ein KI-Modell (das nur Muster kennt) mit einer Live-Suchdatenbank (Retrieval) verbindet, um Halluzinationen zu vermeiden und aktuelle Fakten zu liefern.
- Link zum Paper auf arXiv
- Zum „Gedächtnis“ der KI (Memorization vs. Reasoning):
- Paper: Language Models are Few-Shot Learners (Brown et al., 2020) *
- GPT-3 Paper von OpenAI. Es erklärt, wie riesige Datenmengen (das Pre-Training) dazu führen, dass das Modell ohne spezielle Neu-Programmierung plötzlich Fakten abrufen und Aufgaben lösen kann.
- Link zum Paper auf arXiv
- Zu Halluzinationen (Warum die Live-Suche so wichtig ist):
- Paper: A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions (Ji et al., 2023)
- Zusammenfassung, die wissenschaftlich erklärt, warum KIs sich Dinge ausdenken, wenn sie nur auf ihre Gewichte vertrauen und keine Live-Daten abrufen.
- Link zum Paper auf arXiv
- Zum Nutzeranteil:
- SimilarWeb / Global AI Tracker (Anfang 2026): Zeigt den deutlichen Rückgang von ChatGPTs Monopol (von ca. 87 % auf unter 68 %) zugunsten von Google Gemini auf. (Ideal, um die Verschiebung am Markt zu belegen).
- AIMultiple (LLM Market Share Report, Feb. 2026): Bestätigt den rasanten Anstieg von Gemini auf fast ein Viertel des weltweiten Web-Traffics bei generativer KI.
- Statcounter (KI-Nutzung): Eine weitere hervorragende Standardquelle für Web-Traffic. Sie belegt auch Claudes anhaltenden, aber stabilen Anteil von ca. 2 % im reinen Consumer-Web, während Anthropic laut Branchenberichten im lukrativen Firmenkundengeschäft deutlich stärkere Zahlen schreibt.