Content aus dem Nichts – Wie generiert eine KI Videos?

In den Nachrichten wird immer wieder davon gesprochen, dass große Produktionsstudios wie Netflix bald auf KI setzen werden und es keine oiginellen Inhalte mehr geben wird. Aber ist das denn wirklich so easy, einer KI ein paar Prompts einzuspeisen, zu sagen „mach“ und – boom – der neue oscarprämierte Film ist da?
In einem vorangegangenen Blogbeitrag hatten wir euch über Künstliche Intelligenz im Zusammenhang mit Bildgenerierung erzählt. Wenn ihr den Beitrag verpasst habt, dann lest ihn gerne nach. „Videos sind doch einfach eine Aneinanderreihung von Bildern.“, könnte man jetzt sagen. Warum also noch einen Beitrag? Unterscheidet sich Videogenerierung etwa so stark? Ja und nein.
Eine KI kann aus verschiedenen Prompts Material generieren. Am gängigsten sind Textprompts, bei welchen der Input in schriftlicher Form gegeben wird. Man kann aber auch Bilder als Input geben, die animiert oder erweitert werden, oder auch andere Videos. Für beide visuelle Medien wird der Input definiert, indem Elemente des Bildes identifiziert werden, wie z.B. Wellen, Schiff, Klippe. Auf diese Weise kann die KI das Ganze erweitern und ergänzen.
Genauso wie bei der Bildgenerierung gibt es auch bei Videos zahlreiche Technologien, die es ermöglichen, Konzeptvideos und vieles mehr zu erstellen. Die drei gängigsten möchten wir euch heute präsentieren.
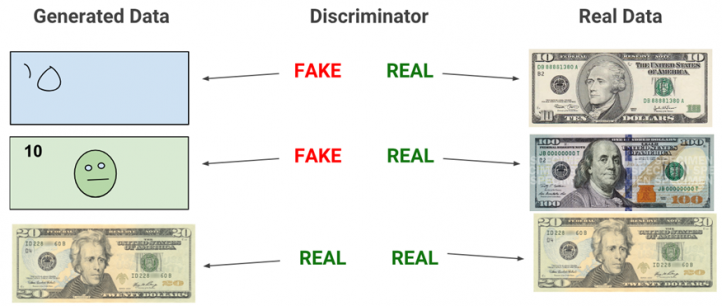
Die GAN Methode haben wir euch ja bereits im letzten Beitrag vorgestellt, aber auch in Videoerstellung findet sie Verwendung, deshalb gibt es hier ein kurzes Recap:
Bei der GAN Methode vergleicht das diskriminierende Netzwerk die vom generierenden Netzwerk erstellen Medien mit dem Referenzmaterial und weist es so lange ab, bis es keinen Unterschied mehr erkennen kann. Dieses Material wird dann als Output gegeben.
Eine andere Möglichkeit ist die Variational Autoencoders Methode (kurz: VAE). Hierbei werden die Trainingsvideos, durch welche das System lernt, dekodiert. Sinngemäß werden sie also in Einzelteile zerlegt, aus welchen die KI ein neues Video generieren kann. Man kann sich das ganze in Form von Bauklötzen vorstellen. Man zerlegt ein Bauhaus in die einzelnen Bauklötze, um daraus etwas Neues zu bauen. Technisch betrachtet geschieht da natürlich einiges mehr, aber fürs Grundverständnis reicht das völlig.

Die dritte Methode, die wir euch heute vorstellen wollen, sind die Recurrent Neural Networks (kurz: RNNs). Hierbei schaut die KI bei der Generierung den vorangegangenen Frame an und knüpft an diesen an. Der Arbeitsablauf ähnelt also einem Daumenkino, welches ebenfalls Bewegungen und Farben aus vorangegangen Frames nimmt. Diese Netzwerke glänzen durch ihr Kurzzeitgedächtnis, dank dessen sie Informationen von einer Sequenz zur nächsten tragen können.
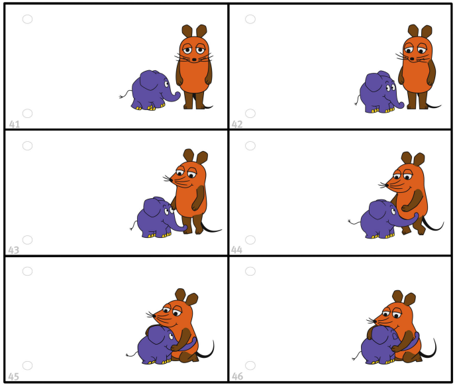
Keine Methode läuft zurzeit einwandfrei. In vielen Fällen kann man noch sogenannte „Uncanny Effekte“ beobachten, bei welchen Gelenke sich nicht so bewegen, wie sie sollten, physikalische Gesetze außer Acht gelassen werden oder seltsame Hybrid-Geschöpfe entstehen, die nicht klar identfizierbar sind. Für kurze Animationen, wie einfache Bildanimationen, lassen sich KI-Tools bereits besser verwenden. Vollwertige Videoproduktionen allein in die Hand einer KI zu geben, ist aktuell nicht ratsam. Der oscarprämierte, sich selbst schreibende und produzierende Film muss also noch ein wenig warten.